Architecture overview¶
This document describes the architecture of Crawl Frontier and how its components interact.
Overview¶
The following diagram shows an overview of the Crawl Frontier architecture with its components (referenced by numbers) and an outline of the data flow that takes place inside the system. A brief description of the components is included below with links for more detailed information about them. The data flow is also described below.
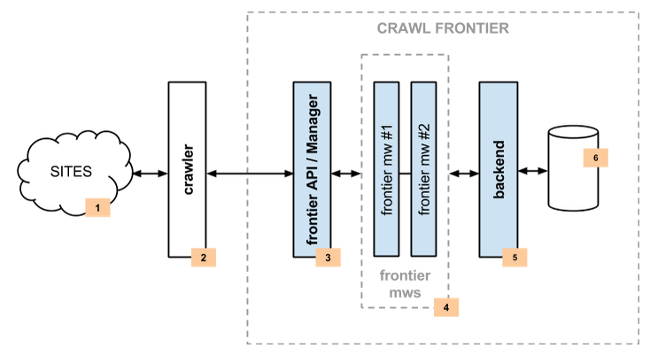
Components¶
Crawler¶
The Crawler (2) is responsible for fetching web pages from the sites (1) and feeding them to the frontier which manages what pages should be crawled next.
Crawler can be implemented using Scrapy or any other crawling framework/system as the framework offers a generic frontier functionality.
Frontier API / Manager¶
The main entry point to Crawl Frontier API (3) is the FrontierManager object. Frontier users, in our case the Crawler (2), will communicate with the frontier through it.
Communication with the frontier can also be done through other mechanisms such as an HTTP API or a queue system. These functionalities are not available for the time being, but hopefully will be in future versions.
For more information see Frontier API.
Middlewares¶
Frontier middlewares (4) are specific hooks that sit between the Manager (3) and the Backend (5). These middlewares process Request and Response objects when they pass to and from the Frontier and the Backend. They provide a convenient mechanism for extending functionality by plugging custom code.
For more information see Middlewares.
Backend¶
The frontier backend (5) is where the crawling logic/policies lies. It’s responsible for receiving all the crawl info and selecting the next pages to be crawled.
May require, depending on the logic implemented, a persistent storage (6) to manage Request and Response objects info.
For more information see Backends.
Data Flow¶
The data flow in Crawl Frontier is controlled by the Frontier Manager, all data passes through the manager-middlewares-backend scheme and goes like this:
- The frontier is initialized with a list of seed requests (seed URLs) as entry point for the crawl.
- The crawler asks for a list of requests to crawl.
- Each url is crawled and the frontier is notified back of the crawl result as well of the extracted links the page contains. If anything went wrong during the crawl, the frontier is also informed of it.
Once all urls have been crawled, steps 2-3 are repeated until crawl of frontier end condition is reached. Each loop (steps 2-3) repetition is called a frontier iteration.